How to call Facebook API using python? How to extract Facebook campaign data using Facebook API and python?
Hi Everyone, hope you are keeping well. Today we are going to see how to develop a python code to extract Facebook campaigns and profile data using Facebook API (Facebook Marketing API).
Building Applications having integration with social networks are increasingly becoming popular for various purposes. Extracting data from social channels is the key part of it.
Whatever may be the purpose, connecting to social media requires your application to go through certain authentication and authorization process. For that, you need to go through the basic setup and generate a list of credentials. The credentials you going to need are – Access Token, App Id, App Secret, and Account Id. If you have it then you are good to go. In case you don’t have those credentials, no worry, you need to go through just 3 simple steps to set up a Facebook developer account and generate the above credentials.
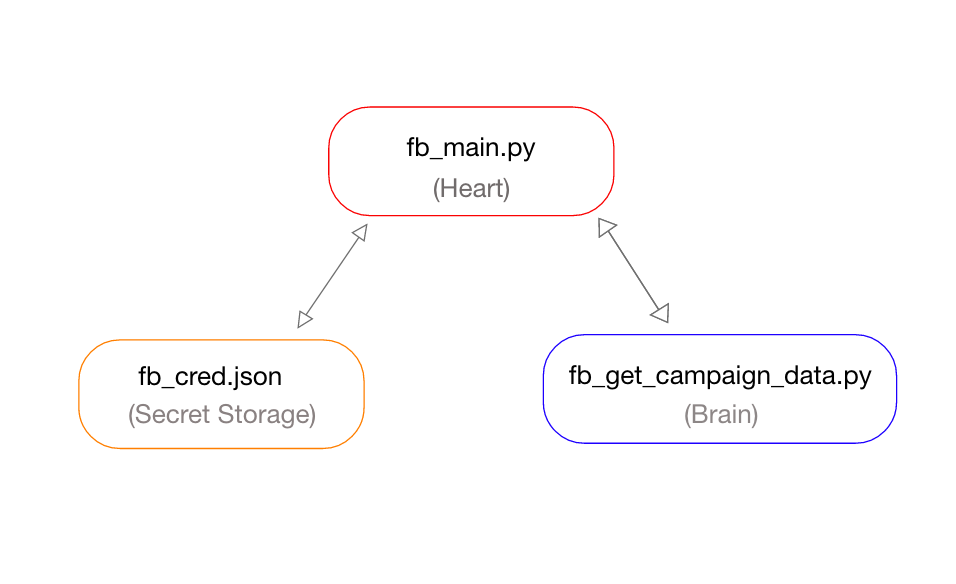
Code Structure:-
Without boring you off from a long setup intro, let’s have a look at how you can run a python code to connect to Facebook through Facebook API (Facebook Marketing API) and pull your profile data or analytics data (campaigns and ads data).
1. Create a JSON file to store Facebook API credentials
A JSON file is the best way to store any credentials required for your automation code. It enables easy scalability and flexibility for maintenance and updates.
Create a JSON file “fb_api_cred.json”
Sample structure, you can customize according to your need.
Note: I used client_id to maintain only once JSON from multiple clients and for easy scalability across clients.
{
"client_name":
{
"client_id" :1,
"Access_token":"replace with your access token",
"App_id":"replace with your app id",
"App_secret":"replace with your app secret",
"Account_id":"replace with ad account id of client"
}
}
2. Create the main file (The executable file – controller/initiator)
This python file will be used for flow control. Consider this file as the heart of this Facebook campaign data extraction project. Save this file as “fb_main.py”.
#!/usr/local/bin/python3
# command to run this code $ python3 ./python/fb_main.py -d ./filePath/fb_api_cred.config -s 2022-07-05(startDate) -e 2022-07-11(endDate)
import getopt
import sys
import datetime
import os.path
import json
from get_fb_data_query import *
#importing readConfig file function
from readConfig import*
def isFile(fileName):
if(not os.path.isfile(fileName)):
raise ValueError("You must provide a valid filename as parameter")
def readfile(argv):
global cred_file
global s_date
global e_date
try:
opts, args = getopt.getopt(argv,"d:s:e:")
except getopt.GetoptError:
usage()
for opt, arg in opts:
if opt == '-d':
isFile(arg)
cred_file = arg
elif opt == '-s':
s_date = arg
elif opt == '-e':
e_date = arg
elif opt == '-q':
qry_type = arg
else:
print("\n Invalid Option in command line")
if __name__ == '__main__':
try:
timestamp = datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m-%d : %H:%M')
print("DATE : ",timestamp,"\n")
print("Facebook data extraction process Started")
readfile(sys.argv[1:])
#reading client_id json file
cred_file = open(cred_file, 'r')
cred_json = json.load(cred_file)
#Initializing variable with data from cred file
org_id = cred_json[client_name]["id"]
access_token = cred_json[client_name]["access_token"]
app_id = cred_json[client_name]["app_id"]
app_secret = cred_json[client_name]["app_secret"]
account_id = cred_json[client_name]["account_id"]
#call the facebook API query function (i.e get_facebook_campaign_data)
facebook_data_df = get_facebook_campaign_data(app_id,app_secret,access_token,account_id,org_id,s_date,e_date,qry_type)
print("FaceData :\n",facebook_data_df)
print("FaceData :\n",facebook_data_df[["conversions","spend","objective","campaignType"]])
#query_result_column = tuple(facebook_data_df.columns.values)
#print("column name :",query_result_column)
print("\n facebook data extraction Process Finished \n")
except:
print("\n Facebook data extraction processing Failed !!!!:", sys.exc_info())
If you want I can help you out with a python code to generate an access token and the entire process automated. Get in touch with me. This all can be done in 1 hour for you.
3. Create a ReadConfig python file
This file will have a function for processing config files so that we can extract all the credentials from it as and when needed. We are going to import this function as a module in the needed files (i.e in our case fb_main.py file). This file is like a helping hand in this project.
Save this file as “readConfig.py”.
#!/usr/local/bin/python3
class ReadConfig:
def __init__( self, path=''):
self.filePath = path
def __del__(self):
class_name = self.__class__.__name__
print(class_name, "Completed")
def getCongDict(self):
input = open(self.filePath, 'r')
configs = input.read().split('\n')
input.close()
self.configs = {}
for config in configs:
if config == '' or config == None:
continue
try:
config = config.split('\t')
self.configs[config[0]] = config[1]
except:
print('readConfig : Error reading config: ', config)
return self.configs
4. Create a python file implementing Facebook API to extract data
This python file will do the most important work. Extracting data from Facebook Campaigns using Facebook Marketing API is the responsibility python code in this file. Save the file with the name “get_fb_campaign_data.py”. Hence this file acts as the brain of all this project.
#!/usr/bin/python3
import sys
import pandas
import json
from datetime import datetime, timedelta
import datetime
from facebook_business.api import FacebookAdsApi
from facebook_business.adobjects.adaccount import AdAccount
#Function for date validation
def date_validation(date_text):
try:
while date_text != datetime.datetime.strptime(date_text, '%Y-%m-%d').strftime('%Y-%m-%d'):
date_text = input('Please Enter the date in YYYY-MM-DD format\t')
else:
return datetime.datetime.strptime(date_text,'%Y-%m-%d')
except:
raise Exception('get_fb_data_query : year does not match format yyyy-mm-dd')
def get_facebook_campaign_data(app_id,app_secret,access_token,account,org_id,s_date,e_date):
try:
FacebookAdsApi.init(app_id, app_secret, access_token)
account = AdAccount("act_"+account)
campaigns = account.get_campaigns(fields=['id','name','account_id'])
print("Total number of Campaigns :",len(campaigns))
#calling date validation function for start date format check
startDate = date_validation(s_date)
dt = startDate+timedelta(1)
week_number = dt.isocalendar()[1]
#calling date validation function for end date format check
endDate = date_validation(e_date)
#create a dataframe with needed column name
campaign_data_df = pandas.DataFrame(columns=['account_name','account_id','campaign_name','campaign_id',
'impressions','conversions','spend',
'reach','clicks','date_start','date_stop','objective','campaignType'])
#define field to be extracted from facebook campaign
fields=['impressions','conversions','spend','reach','clicks','account_id','account_name','campaign_name','campaign_id','objective','cpc']
#extract data/insights from each campaigns
for campaign in campaigns:
for camp_insight in campaign.get_insights(fields=fields,params={'time_range':{'since':s_date,'until':e_date}}):
campaign_obj = camp_insight["objective"]
#adding cam_insight data to dataframe by converting result to dictionary
campaign_data_df = campaign_data_df.append(dict(camp_insight),ignore_index = True)
campaign_data_df["org_id"] = org_id
campaign_data_df["impressions"] = pandas.to_numeric(campaign_data_df["impressions"])
campaign_data_df["conversions"] = pandas.to_numeric(campaign_data_df["conversions"])
campaign_data_df["spend"] = pandas.to_numeric(campaign_data_df["spend"])
campaign_data_df["clicks"] = pandas.to_numeric(campaign_data_df["clicks"])
campaign_data_df["reach"] = pandas.to_numeric(campaign_data_df["reach"])
campaign_data_df["cpc"] = pandas.to_numeric(campaign_data_df["cpc"])
campaign_data_df["startDate"] = pandas.to_datetime(campaign_data_df["date_start"])
campaign_data_df["endDate"] = pandas.to_datetime(campaign_data_df["date_stop"])
campaign_data_df["week"] = week_number
campaign_data_df["month"] = startDate.month
return campaign_data_df
except:
print("get_fb_data_query Failed",sys.exc_info())
5. Creating Facebook campaign category JSON file
This file has a list of all different types of Facebook campaigns and is categorized into off-site and on-site campaigns. This is a JSON file i.e key: value structure. So we have two keys “off-site” and “on-site”.
Save this file as “campaign_category.json”.
{
"off_site":["VIDEO_VIEW","LEAD_GENERATION","BRAND_AWARENESS","ENGAGEMENT","REACH","MESSAGES","STORE_TRAFFIC","APP_INSTALLS"],
"on_site":["CATALOG_SALES","CONVERSIONS","TRAFFIC","LINK_CLICKS"]
}
Tips:-
- Store JSON files in separate folders say “config” and python files in separate folders say “source” for better structuring and easy maintenance.
- Don’t forget to update the Facebook Marketing API access token, since it expires after 2 months i.e valid only for 2 months.
- For database storing, create a separate file for only the data load process. And since we have used pandas data frame, data load to database table is easy. In some cases it may need a few additional steps, to refine data and its column.
Congratulation! you have successfully developed python code to extract Facebook campaigns and ads data. you can customize the same code to get more data from your Facebook Ads Account.
Hope I was able to solve the problem. If you like this article and think it was easy to understand do share it with your friends and connection. Thank you! see you soon.
For any suggestions or doubts ~ Get In Touch
Checkout out my other API Integration and Coding Solution Guide