
How to Extract LinkedIn Campaign Data with Python: A Step-by-Step Tutorial
Hi Everyone, hope you are keeping well. In this step-by-step guide, you’ll learn how to develop a Python script to extract data from LinkedIn. we’ll explore the development of Python code using LinkedIn API (specifically, the LinkedIn Advertising API) to extract valuable campaign performance data from the LinkedIn Campaigns Manager Account. This data can be used for a variety of purposes, such as marketing research, performance analysis, and competitive analysis. As the demand for social network integration in applications continues to rise, data extraction from social channels takes center stage.
To connect with the LinkedIn Campaign Manager Account, the code application must undergo an authentication and authorization process, typically involving OAuth Authentication. This process requires credentials: Access Token, App ID, App Secret, and Account ID. If you already have these credentials, you’re ready to proceed. But if not, don’t worry. In just three simple steps, we’ll guide you through setting up a LinkedIn Developer account and generating the necessary credentials.

Table of Contents:
- Create a JSON file for Credentials
- Create the Main Python file
- Creating a Data Extraction Process Python file
Quick Access:
Without boring you with a long setup intro, let’s dive into how to run Python code to connect to LinkedIn through the LinkedIn Advertising API and pull campaign data from your LinkedIn Campaign Manager Account.
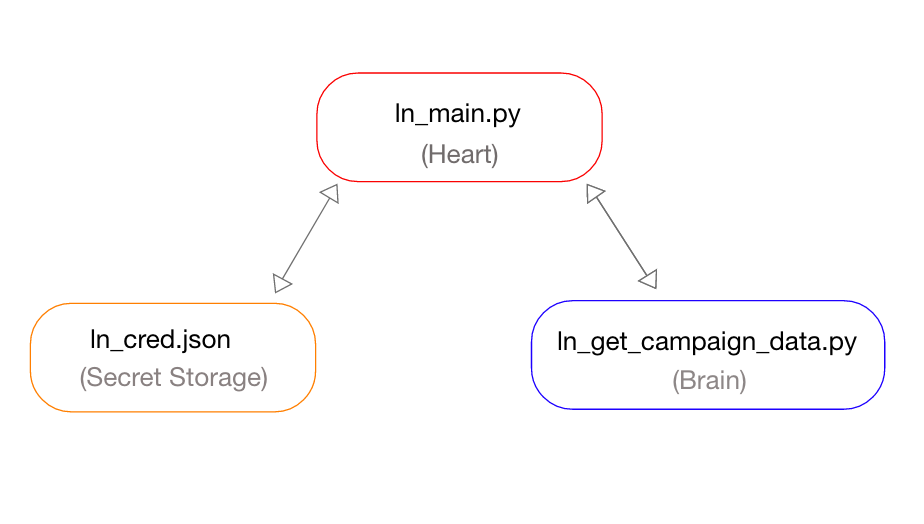
List of files in this project:-
- ln_main.py
- get_ln_campaign_data.py
- ln_cred.json
1. Create a JSON file for Credentials
Storing your credentials in a JSON file is a secure and efficient approach, offering scalability and flexibility for code maintenance and updates. Let’s create a JSON file named “ln_cred.json” to manage your LinkedIn API credentials.
Below is a sample structure for the JSON file, which you can customize as needed.
{
"access_token":"Replace it with LinkedIn access token",
"client_id":"Replace it with LinkedIn app ID",
"Client_secret":"Replace it with LinkedIn app secret",
"account_id":"Replace this with LinkedIn ads account ID"
}
2. Create a Main Python file
The main Python file is the heart of your LinkedIn campaign data extraction project, providing essential flow control. You will execute this file to run the project. Let’s name this crucial file “ln_main.py” for easy access and management.
#!/usr/local/bin/python3
# command to run this code $ python3 ./ln_main.py -s 2022-06-25 -e 2022-06-25
import getopt
import sys
import datetime
import os.path
import json
from get_linkedin_data import *
def readfile(argv):
global s_date
global e_date
try:
opts, args = getopt.getopt(argv,"s:e:")
except getopt.GetoptError:
usage()
for opt, arg in opts:
if opt == '-s':
s_date = arg
elif opt == '-e':
e_date = arg
else:
print("Invalid Option in command line")
if __name__ == '__main__':
try:
timestamp = datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m-%d : %H:%M')
print("DATE : ",timestamp,"\n")
print("\n LinkedIn data extraction process Started")
readfile(sys.argv[1:])
#reading LinkedIn credential json file
cred_file = open("./python/linkedin_cred.json", 'r')
cred_json = json.load(cred_file)
access_token = cred_json["access_token"]
#account_id = cred_json["account_id"]
#call the LinkedIn API query function (i.e get_linkedin_campaign_data)
ln_campaign_df = get_campaigns_list(access_token,account_id)
print("LinkedIn Data :\n",ln_campaign_df)
if not ln_campaign_df.empty:
#get campaign analytics data
campaign_ids = ln_campaign_df["campaign_id"]
campaign_analytics = get_campaign_analytics(access_token,campaign_ids,s_date,e_date)
print("\n campaigns analytics :\n",campaign_analytics)
else:
campaign_analytics = pd.DataFrame()
print("\n LinkedIn data extraction Process Finished \n")
except:
print("\n !! LinkedIn data extraction processing Failed !! \n", sys.exc_info())
3. Creating a Data Extraction Process Python file
This Python file will do the most critical work. Extracting data from LinkedIn Campaigns and LinkedIn Ads using LinkedIn Advertising API. Save the file with the name “get_linkedin_data.py”. Hence this file acts as the brain of this project.
In the below code, I am getting only limited fields(metrics) from a LinkedIn Campaign. You can add more fields from the LinkedIn Metrics list in the below code to get more data.
#!/usr/bin/python3
import requests
import pandas as pd
import sys
import json
from datetime import datetime, timedelta
import datetime
import re
from urllib import parse
#Function for date validation
def date_validation(date_text):
try:
while date_text != datetime.datetime.strptime(date_text, '%Y-%m-%d').strftime('%Y-%m-%d'):
date_text = input('Please Enter the date in YYYY-MM-DD format\t')
else:
return datetime.datetime.strptime(date_text,'%Y-%m-%d')
except:
raise Exception('linkedin_campaign_processing : year does not match format yyyy-mm-dd')
def get_campaigns_list(access_token,account):
try:
url = "https://api.linkedin.com/v2/adCampaignsV2?q=search&search.account.values[0]=urn:li:sponsoredAccount:"+account
headers = {"Authorization": "Bearer "+access_token}
#make the http call
r = requests.get(url = url, headers = headers)
#defining the dataframe
campaign_data_df = pd.DataFrame(columns=["campaign_name","campaign_id","campaign_account",
"daily_budget","unit_cost","campaign_status","campaign_type"])
if r.status_code != 200:
print("get_linkedIn_campaigns_list function : something went wrong :",r)
else:
response_dict = json.loads(r.text)
#print(response_dict)
if "elements" in response_dict:
campaigns = response_dict["elements"]
print("\nTotal number of campain in account : ",len(campaigns))
#loop over each campaigns in the account
campaign_list = []
for campaign in campaigns:
tmp_dict = {}
#for each campign check the status; ignor DRAFT campaign
if "status" in campaign and campaign["status"]!="DRAFT":
try:
campaign_name = campaign["name"]
except:
campaign_name = "NA"
tmp_dict["campaign_name"] = campaign_name
try:
campaign_id = campaign["id"]
except:
campaign_id = "NA"
tmp_dict["campaign_id"] = campaign_id
try:
campaign_acct = campaign["account"]
campaign_acct = re.findall(r'\d+',campaign_acct)[0]
except:
campaign_acct = "NA"
tmp_dict["campaign_account"] = campaign_acct
try:
daily_budget = campaign["dailyBudget"]["amount"]
except:
daily_budget = None
tmp_dict["daily_budget"] = daily_budget
try:
unit_cost = campaign["unitCost"]["amount"]
except:
unit_cost = None
tmp_dict["unit_cost"] = unit_cost
campaign_status = campaign["status"]
tmp_dict["campaign_status"] = campaign_status
campaign_list.append(tmp_dict)
campaign_data_df = pd.DataFrame.from_records(campaign_list)
try:
campaign_data_df["daily_budget"] = pd.to_numeric(campaign_data_df["daily_budget"])
campaign_data_df["unit_cost"] = pd.to_numeric(campaign_data_df["unit_cost"])
except:
pass
else:
print("\n key *elements* missing in JSON data from LinkedIn")
return campaign_data_df
except:
print("\n get_campaigns_list Failed :",sys.exc_info())
def get_campaign_analytics(access_token,campaigns_ids,s_date,e_date):
try:
#calling date validation funtion for start_date format check
startDate = date_validation(s_date)
dt = startDate+timedelta(1)
week_number = dt.isocalendar()[1]
#calling date validation funtion for end_date format check
endDate = date_validation(e_date)
#defining the dataframe
campaign_analytics_data = pd.DataFrame(columns=["campaign_id","start_date","end_date",
"cost_in_usd","impressions","clicks"])
fields = "costInUsd, impressions, clicks"
campaign_list = []
for cmp_id in campaigns_ids:
#Building api query in form of url
dateRange_start = "dateRange.start.day="+str(startDate.day)+"&dateRange.start.month="+str(startDate.month)+"&dateRange.start.year="+str(startDate.year)
dateRange_end = "dateRange.end.day="+str(endDate.day)+"&dateRange.end.month="+str(endDate.month)+"&dateRange.end.year="+str(endDate.year)
url = "https://api.linkedin.com/v2/adAnalyticsV2?q=analytics&pivot=CAMPAIGN&"+dateRange_start+"&"+dateRange_end+"&timeGranularity=ALL&campaigns[0]=urn:li:sponsoredCampaign:"+str(cmp_id)+"&fields="+fields
#defining header for authentication
headers = {"Authorization": "Bearer "+access_token}
#make the http call
r = requests.get(url = url, headers = headers)
if r.status_code != 200:
print("*get_LinkedIn_campaign : something went wrong :",r)
else:
response_dict = json.loads(r.text)
if "elements" in response_dict:
campaigns = response_dict["elements"]
for campaign in campaigns:
tmp_dict = {}
cmp_costInUsd = float(campaign["costInUsd"])
tmp_dict["cost_in_usd"] = round(cmp_costInUsd,2)
cmp_impressions = campaign["impressions"]
tmp_dict["impressions"] = cmp_impressions
cmp_clicks = campaign["clicks"]
tmp_dict["clicks"] = cmp_clicks
tmp_dict["campaign_id"] = cmp_id
tmp_dict["start_date"] = startDate
tmp_dict["end_date"] = endDate
tmp_dict["week"] = week_number
tmp_dict["month"] = startDate.month
campaign_list.append(tmp_dict)
else:
print("\nkey *elements* missing in JSON data from LinkedIn")
campaign_analytics_data = pd.DataFrame.from_records(campaign_list)
campaign_analytics_data["start_date"] = startDate
campaign_analytics_data["end_date"] = endDate
return campaign_analytics_data
except:
print("\n* get_campaign_analytics Failed :",sys.exc_info())
Elevate your LinkedIn API integration with my support. Whether it’s fetching campaign group and ads data, upgrading to the latest LinkedIn API, or automating token refresh for uninterrupted access, I’ve got the solutions you need. Let’s chat about your specific requirements through the Contact Form.
Tips:-
- Store JSON files in separate folders say “config” and python files in separate folders say “source” for better structuring and easy maintenance.
- Don’t forget to update the LinkedIn Advertising API access token, since it expires after 2 months i.e. valid only for 2 months.
- For database storing, create a separate file for only the data load process. And since we have used a pandas data frame, data load to the database table is easy. In some cases it may need a few additional steps, to refine data and its column.
Congratulations! You have successfully developed Python code to extract LinkedIn campaigns and ads data. You can also look at Python code to extract LinkedIn Profile data (i.e. LinkedIn Account Details).
Hope I was able to solve the problem. If you like this article and think it was easy to understand do share it with your friends and connection. Thank you! See you soon.
For any suggestions or doubts ~ Get In Touch
Checkout out my other API Integration and Coding Solution Guide